[python]2つの項目の値に応じてデータの分布を可視化する
- 2021年3月27日
- 読了時間: 2分
更新日:2021年8月21日
概要
データの分布を可視化するにはseabornのcountplotやdistplotなどが使えます。また、ある項目の値に応じてデータの分布を可視化したい場合は、jointplotを使ったり、countplotの引数hueを利用したりできます(例:図1)。以前、各変数の属性(離散量か連続量か)に応じてある項目の値に応じた分布を可視化するメソッドを紹介しました。
今回はそれを拡張して、2つの項目の値に応じたデータの分布を可視化するメソッドを紹介します。

方法
説明変数(分布を調べたい変数)と目的変数(これの値に応じた分布を調べたい)の属性に対する適切なメソッドは以下のようになります。

以前作成したvisualize_dataメソッドの引数に新たに引数hueを追加します。これに2つ目の分類データのkey名を渡します。
def visualize_data(data, target_col, categorical_keys=None, hue=None):jointplot、violineplotの場合
これらのメソッドではまだ引数hueを使っていないので、引数hueを利用できます。
sg=sns.jointplot(x=key, y=target_col, data=data, height=length*2/3,
hue=hue)countplotの場合
countplotの場合はすでに引数hueを使ってしまっています。そこで、2つ目のデータの値毎にプロットを分けることにします。
使用するメソッドをcatplotに変更し、kindを'count'に設定します。catplotの引数rowに変数を渡すと、その変数ごとにプロットを分けてくれます。(rowに渡した場合は横に、colに渡した場合は縦に並びます。)
sns.catplot(x=key, data=data, hue=target_col, row=hue, kind='count')distplotの場合
同じく引数hueは使ってしまったので、こちらも2つめのデータの値毎にプロットを分けます。
g=sns.FacetGrid(data, hue=target_col, row=hue)
g.map(sns.distplot, key, ax=axes[1], kde=False)全体では以下のようになります。内部で使ってる独自メソッドについては前回のページを見てください。
def visualize_data(data, target_col, categorical_keys=None, hue=None):
keys=data.keys()
if categorical_keys is None:
categorical_keys=keys[[is_categorical(data, key) for key in
keys]]
for key in keys:
if key==target_col or key==hue:
continue
length=10
subplot_size=(length, length/2)
if (key in categorical_keys) and (target_col in categorical_keys):
r=cramerV(key, target_col, data)
fig, axes=plt.subplots(1, 2, figsize=subplot_size)
sns.countplot(x=key, data=data, ax=axes[0])
sns.catplot(x=key, data=data, hue=target_col, row=hue,
kind='count')
plt.title(r)
plt.tight_layout()
plt.show()
elif (key in categorical_keys) and not (target_col in
categorical_keys):
r=correlation_ratio(cat_key=key, num_key=target_col,
data=data)
fig, axes=plt.subplots(1, 2, figsize=subplot_size)
sns.countplot(x=key, data=data, ax=axes[0])
sns.violinplot(x=key, y=target_col, data=data, ax=axes[1],
hue=hue)
plt.title(r)
plt.tight_layout()
plt.show()
elif not (key in categorical_keys) and (target_col in
categorical_keys):
r=correlation_ratio(cat_key=target_col, num_key=key,
data=data)
fig, axes=plt.subplots(1, 2, figsize=subplot_size)
sns.distplot(data[key], ax=axes[0], kde=False)
g=sns.FacetGrid(data, hue=target_col, col=hue)
g.map(sns.distplot, key, ax=axes[1], kde=False)
axes[1].set_title(r)
axes[1].legend()
plt.title(r)
plt.tight_layout()
plt.show()
else:
r=data.corr().loc[key, target_col]
sg=sns.jointplot(x=key, y=target_col, data=data,
height=length*2/3, hue=hue)
plt.title(r)
plt.show() 結果は以下のようになります(一部だけ表示)。'Cover_Type'、'result'の2つの項目の値に応じてデータの分布をプロットします。
visualize_data(data=data_res, target_col='Cover_Type', hue='result')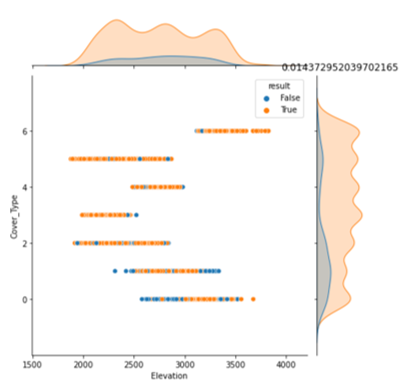

最後に
使い方としては、モデルによる予測結果をデータの列に追加し、これとターゲットの値との2つの値に応じてデータの分布を見る、というようなものが多いです。
記事内で扱ったメソッドはgithubに上げてあります。



コメント