検索
[python]機械学習で間違えた部分を可視化する
- 2021年3月28日
- 読了時間: 2分
更新日:2021年8月21日
概要
機械学習を行っていると、「作成したモデルがどのデータで間違えているのか」を知りたくなることがあります。すべてのカテゴリに対して等しく間違えているのか?それともあるカテゴリのデータだけ間違える確率が高いのか?などが分かればモデルの修正方法のヒントになるかもしれません。
そのようなメソッドを作ったのでご紹介します。
方法
以下のようなメソッドを作成します。
def wrong_rate(data, target_key, pred, real):
first_key=data.keys()[0]
if first_key==target_key:
first_key=data.keys()[1]
wrong=pred!=real #1 間違っている部分
data_wrong=data[wrong]
#2 間違っている個数を数える
data_wrong_group=data_wrong.groupby(target_key).count()
[first_key].reset_index().rename(columns=
{first_key: 'Count'}).set_index(target_key)
#3 全体の個数
data_count=data.groupby(target_key)
[first_key].count().reset_index().rename(columns=
{first_key: 'Count'}).set_index(target_key)
#4 規格化
data_wrong_group/=data_count
return data_wrong_groupdata: データ target_key: 予測するkey名 pred:予測値 real: 実際の値
まずは予測が間違っている部分を求めます(1)。
次に、間違っているデータをターゲットでグループ分けし、それぞれ個数を数えます(2)。
また、各ターゲットの個数を求め(3)、規格化します(4)。
以下のように使います。(データはkaggleのForest Cover Type)
wrong_rate(data=data_test, target_key='Cover_Type',pred=y_pred,
real=y_test) 
0、1、2のデータに対して正解率が低いことが分かります。
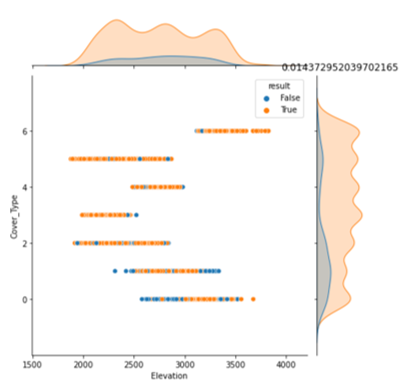
さらにこのデータをグラフで可視化します。2つの項目の値に応じてデータの分布を可視化する で作成したメソッドを使い、ターゲット(Cover_Type)と正解か否かの2項目の値に応じてデータの分布を表示してみます。
data_res=data_test.copy()
data_res['result']=y_test==y_pred
visualize_data(data=data_res, target_col='Cover_Type', hue='result')data_test: テストデータ y_test: ターゲットのテストデータ y_pred: 予測値
結果は以下のようになります。(一部のみ)

最後に
で、この結果をどう活用するのか、については自分もまだ模索中です、、、
記事内で扱ったメソッドはgithubに上げてあります。



コメント