画像認識で画像のリサイズと正解率、判定時間の関係を調べてみた
- 2021年6月4日
- 読了時間: 2分
概要
現在、カメラで撮影した画像を機械学習で判定する、というプロジェクトを作成しています。その際、撮影した画像そのままだと処理が重くなり、学習や判定に時間がかかってしまうので、対策として画像を粗くしてみようかと思いました。
しかし、粗くすればそれだけ認識の正解率も落ちると考えられますので、これらのトレードオフを調べてみました。
検証1:学習
画像のリサイズ
opencvのresize()メソッドで画像をリサイズできます。画像ファイルを読み込んで指定のスケールでリサイズするメソッドは以下のようになります。
def fileToImg(file, scale):
img=cv2.imread(file, cv2.IMREAD_GRAYSCALE)
if scale!=1:
img=cv2.resize(src=img, dsize=(0, 0), fx=scale, fy=scale)
img=img.astype('float')
img/=255
img=img.reshape(img.shape[0], img.shape[1], 1)
return imgこれを用いて、以下のように学習データを作成します。
def makeData(scale):
files=glob.glob('*.png')
datas=[]
labels=[]
for i, file in enumerate(files):
img=fileToImg(file, scale)
datas.append(img)
label=fileToLabel(file) #ファイル名からラベルを作成 詳細は略
labels.append(label)
datas=np.array(datas)
labels=np.array(labels)
labels=to_categorical(labels)
return datas, labels学習モデル
判定の内容は、画像を内容によって01の2値に分類するタスクです。
画像認識には畳み込みニューラルネットワークを用います。実装はkerasで行いました。
def makeModel(input_shape):
model=tensorflow.keras.models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=input_shape))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(2, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy',
metrics=['accuracy'])
return modelなお、正解率は以下で測定します。
def getScore(model, x_test, y_test):
y_pred=model.predict(x_test)
y_pred_c=np.argmax(y_pred, axis=1)
y_test_c=np.argmax(y_test, axis=1)
score=accuracy_score(y_pred_c, y_test_c)
return scoreトレードオフの測定
以下のメソッドでリサイズと正解率、学習時間のトレードオフを調べます。
def measureScaleEffect(scale):
datas, labels=makeData(scale) #学習データを作成
x_train, x_test, y_train, y_test=train_test_split(datas, labels,
random_state=0)
model=makeModel(datas[0].shape) #学習モデルを作成
start=time.time()
model.fit(x_train, y_train, epochs=10, batch_size=32, verbose=0)
elapsed=time.time()-start #学習時間
score=getScore(model, x_test, y_test)
return score, elapsed, model結果
上記メソッドを様々なスケールで行った結果、以下のようになりました。

画像を1辺0.6倍にすると、正解率は保ったまま学習にかかる時間を約半分にできました。
検証2:予測
ただ、実際は学習については夜中に走らせておけばいいのであまり時間は気になりません。より重要なのは予測にかかる時間です。
予測はリアルタイム性が求められる上に、場合によってはスペックの高くないマシンで行わなければいけない場合もあります。(例えば今回のプロジェクトではraspberry piで予測をします)
そこで、予測時間についても、画像のリサイズとのトレードオフを検証してみました。
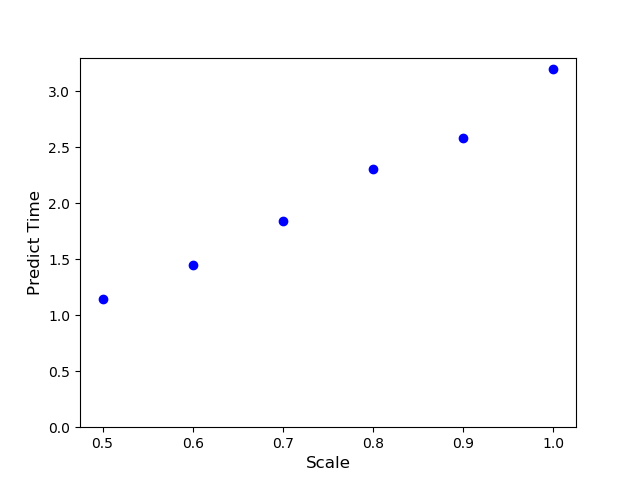
やはりリサイズ率を0.6にすると予測にかかる時間も約半分にできました。
結論
画像を1辺0.6倍にすると、正解率はそのまま、学習、予測にかかる時間を半減できる。
最後に
結果についてはどのようなモデルを組むか、どのような判定をするのか、によって変わってくると思いますので参考程度にお願いします。



コメント